Introduction
In modern data intensive computing, the parallel computing capability is critical for high-performance computing architecture. According to the Flynn’ taxonomy, based on their execution model, the computer architecture can be classified into:
- Single Instruction, Single Data (SISD)
- Single Instruction, Multiple Data (SIMD)
- Multiple Instruction, Single Data (MISD)
- Multiple Instruction, Multiple Data (MIMD) and
- Single Instruction, Single Thread (SIST)
- Single Instruction, Multiple Thread (SIMT).
A thread is the smallest sequence of programmed instructions that can be managed independently. Threads within the same process share the resource, and in contrast, threads in different processes do not share the resource.
SMID vs SIMT
This blog we mainly focus on discussing the difference between SMID and SIMT.
SIMD
Based on the description in wikipedia, SIMD denotes a single insturction is simutaneously applied to multiple different data stream. SIMD improve the data-level parallelism as it allow multiple data to be processed simutaneously (reduce #clock-cycles compared to its sequential counterpart).
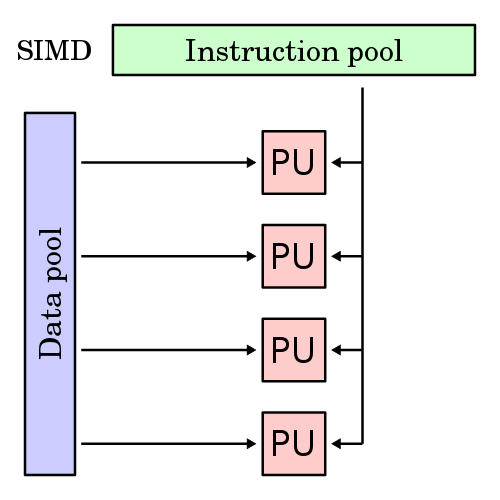
Figure: Illustration of SIMD architecture, and each Processing Unit (PU) is shown for a uni-core or multi-core computer. As all the PUs fetch the data from the data pool (central memory), we can consider it is a pipelined processor under the SIMD category. The cluster of PUs can be considered as a vector unit.
In Flynn’s paper (1972), the SIMD architeture is further divided into:
- Array Processor (SIMT): multiple PEs recieve the identical instruction to execute, and each PE has its own seperate and distinct memory and register file.
- Pipelined processor: multiple PEs recieve the identical instruction to execute, and PEs share the same memory (read and write fragment of data from/to the memory).
- Associative processor (aka predicted/masked SIMD): PEs receive the identical instruction, but each PE decides whether to perform the execution or skip it w.r.t the local data.
According to description, there are multiple SIMT processor appears before the NVIDIA GPU (e.g., SOLOMON, Aspex’s ASP), why only NVIDIA GPU is considered as the first SIMT processor? Is that the NVIDIA GPU is the first commercial GPU that is widely used in the industry?
Some extension on the SIMT.
SMIT is defined in Flynn’s taxonomy, which cites SOLOMON and ILLIAC IV as the representative SIMT processor in its paper.
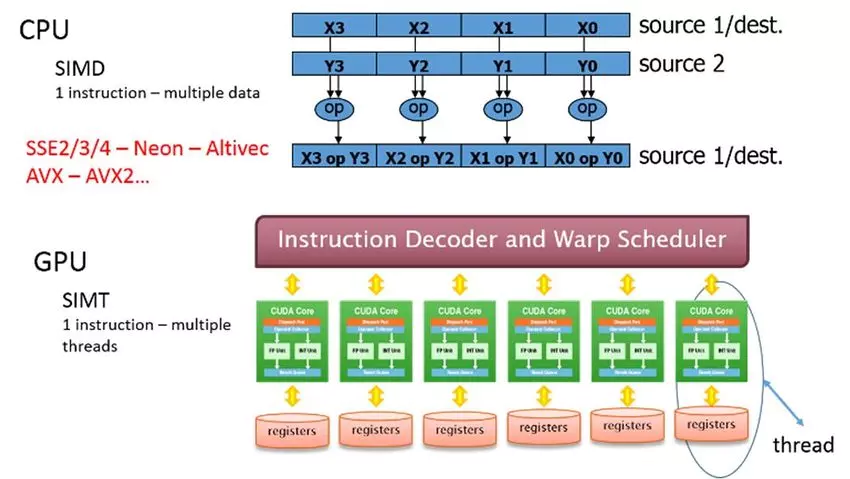
Figure: CPU use SIMD and GPU use SIMT for parallel processing.
Aspex Microelectronics Associative String Processor (ASP)
ASP consider itself as “massive wide SIMD” but had bit-level ALUs and bit-level prediction (i.e., associative processing). Need an additional blog to discuss the details of ASP.
One thing I notice which is interesting that the writer show the ASP achieve 100~1000MOPS/$\$ 1000$, where we should always focus on computing power/$\$ $. This also leads the memory industry as well (bit/$\$ $).
Simutaneous Multithreading (SMT) and Hyperthreading (HT) for ILP
SMT and HT are the same but used/introduced by differnet companies, where SMT is introduced by AMD, and HT is introduced by Intel. The SMT is a technique to improve the efficiency of superscalar CPU with hardware multi-threading.

Figure: Two way superscalar processor. Two instructions are fetched and decoded in two-way superscalar CPU. 1st instruction is an integer or memory access, and 2nd instruction is floating-point instruction.
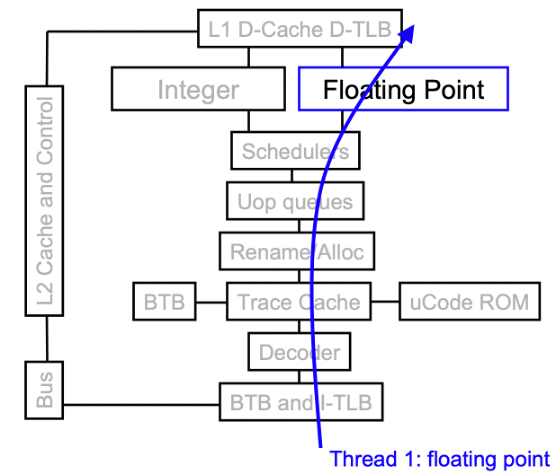
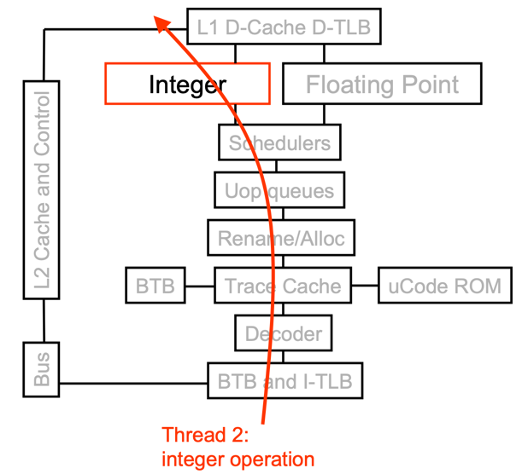
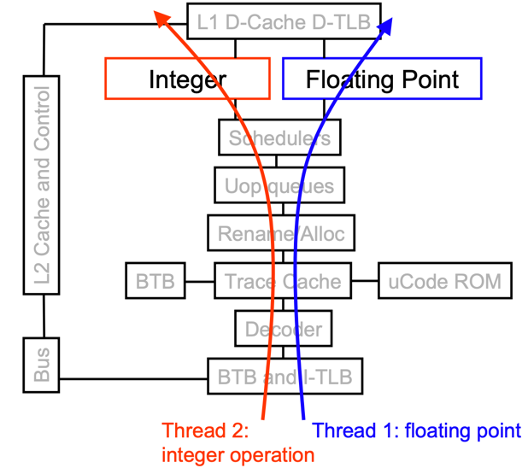
Figure: Without SMT, only single thread can run at any given time. Even with SMT, INT/FP arithmetic unit cannot run two operations both in INT/FP.
Superscalar processor is a CPU that can execute multiple instructions per clock cycle. The superscalar processor can be super-pipelined processor. besides, VLIW is interesting, need a specific blog to discuss it.
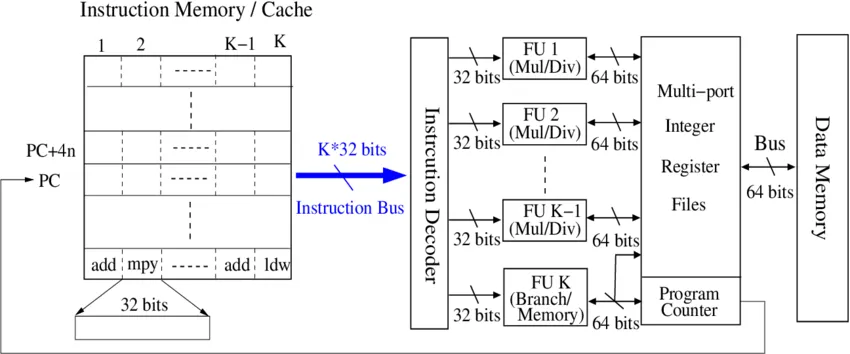
Figure: A classic architecture with VLIW execution model.
For both the VLIW (Very Large Instruction Window) and superscalar processor, they launch and execute multiple instructions per clock cycle. However, a distinct difference between superscalar and VLIW is that VLIW is a static instruction scheduling (relying on compiler), while superscalar is a dynamic instruction scheduling (relying on hardware) for identify paralleable instructions.
References
[1] https://en.wikipedia.org/wiki/Flynn%27s_taxonomy
[2] https://www.hardwaretimes.com/simd-vs-simt-vs-smt-whats-the-difference-between-parallel-processing-models/
[3] Simultaneous Multithreading: Maximizing On-Chip Parallelism. https://www.princeton.edu/~rblee/ELE572Papers/SMT_Eggers.pdf
[4] VLIW processor. (in chinese) https://zhuanlan.zhihu.com/p/337749676
[5] Lea, R. M. (1988). “ASP: A Cost-Effective Parallel Microcomputer”. IEEE Micro. 8 (5): 10–29. doi:10.1109/40.87518. S2CID 25901856.